I set out to make a tool to enable AI assisted selling on eBay and instead spent a month writing a coding agent called OrgChart:
 GarrettPeake
GarrettPeakeThe theory was that a hierarchy of coding agents would enable the same level of organization we see in real engineering orgs. Each level need not concern itself with technical/implementation details of the levels far above and below them. This should produce a system that can effectively manage large scale tasks without any single agent becoming overloaded. The foreseeable downsides to this approach are that a single agent with all of the knowledge would generally perform better than many with small pieces of the puzzle and agents having to pass around context and task specs wastes tokens and therefore time and money. Claude Code does this for some small things, but only delegates one level deep and only for simpler tasks.
You can try it out in alpha now:


npm i -g orgchart-agent
orgchartDisclaimers: This project is by no means complete but it is usable. You'll need an OpenRouter API key in your environment. If you are an iTerm2 user the interface will flicker.
A Multi-Agent Agent
How OrgChart works
First some terminology:
- LLM: Large language model, this refers to the model agnostic of any system prompt or tools
- Harness: The system which utilizes an LLM for a particular task
- Agent: A harnessed LLM
In OrgChart each Agent in the system has a level, model, system prompt, and set of tools. The DelegateWork tool enables agents with a level above zero to delegate tasks as often as they want to any agent of a lower level and the AttemptCompletion tool enables agents to yield control back to their requester. The goal is to enable every agent in the system to achieve their given task without corroding their context and to enable the use of cheaper or faster models for tasks that don't require the best model. Every agent starts with fresh context only containing its own system prompt and its assigned task.
Let's have OrgChart help explain the agent structure with some PlantUML
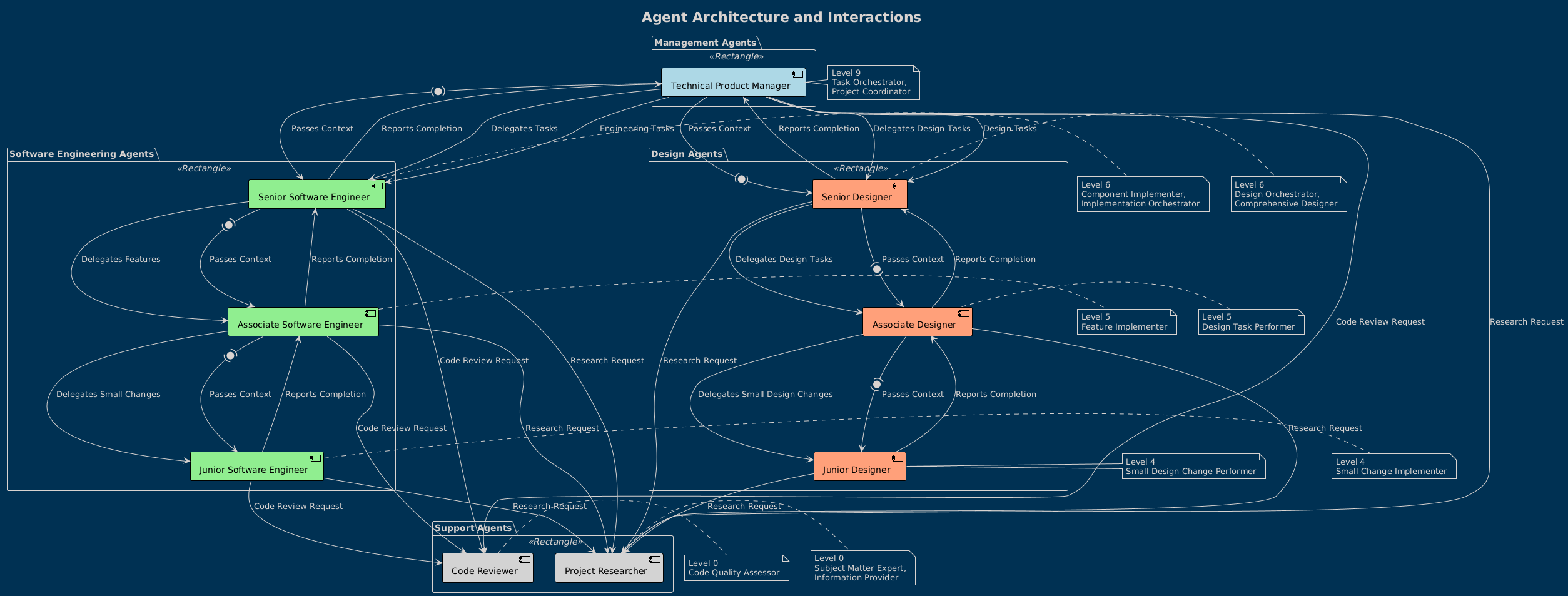
The default agent is the Technical Product Manager, but /agent allows you to choose which agent you want to talk to. The TPM's sole job is to break down a task into components then delegate those components to designers and engineers, thus it has no read/write capabilities. Designers and engineers have junior, associate, and senior levels which allow the respective disciplines to further break down tasks. The designer concept is to separate the code deep-dive from the implementation process to keep context clean.
If we ask for something more complex like creating a plain HTML, JS, CSS stereo audio generator, we can see multiple levels of delegation as shown below:

To enable many agents to operate through the same interface we define each agent as a node in a directed acyclic graph. Each node is a state machine with a step function invoked on a clock and each edge is a "conversation" – a slot for a single message. Only one agent is ever active at a time as parent agents will wait for sub-agents to use their conversations to yield back control. After an agent states that it has completed its task, it cannot be revived apart from the root agent which persists between user interactions. The user can hit escape to pause the currently executing agent or send a message to it.
The only context shared between the agents is what is put in the conversation between those agents. I found that LLMs were difficult to coerce into passing enough context for the subagent to properly pick up where it was needed. The same went for the sub-agents often not providing enough information for the parent to continue properly.
To try to remedy this issue, I created the ContinuousContext which is a single context shared by all agents and updated whenever there is a transition between agents. The version currently implemented reads the entirety of the project files and uses the GPT-OSS-120B model running on Cerebras to create a detailed document with all of the information on the project. Since that model executes at 1-4k tok/s it can ingest a codebase and generate this summary document in only 10-20s for $0.03-0.05. While agents operate there is a file watcher that records all mutations and whenever a new agent is spawned or an agent exits, the context is updated (if there are mutations) and given to the now active agent. I saw that this increased the cohesion of the agents performing large tasks.
As part of the continuous context, I wanted the AI to automatically ignore files that weren't relevant. In my case, it was specifically package-lock.json which is generally not part of the .gitignore. To fix this there's a /aiignore command which uses the same fast LLM to generate a .aiignore file containing patterns which are hidden from the OrgChart.
Future Directions
Ideas and patterns for coding agents
A smart-enough but very fast model has the potential to be used in many ways to enhance the capabilities and coordination of the actual agents:
- To enhance the subtask prompts to sub agents with relevant context or write the completion summaries for the sub agents to speed up the context transfer process. (which is the major slowdown currently)
- To summarize the results of bash commands into only what's useful to the agent. This is implemented in OrgChart as a boolean option in the bash tool so agents can choose to see the raw output, but most often don't need to.
- To act as a universal language server, enabling extracting public/exported symbols and identifying semantic issues.
- To act as a tool for finding the exact place in code a change belongs, similar to the proposed LoCAgent.
- To automatically review any diff before it makes it to the user so things like hallucinated imports or duplicated utilities can be caught and fixed.
- To act as a diff-apply model similar to more expensive post-trained models. (see issues with targeted edits below for why this is useful)
- Add a conversational layer in front of MCP. Rather than giving every agent access to, for example, Context7 we can define a Context7 subagent that can answer any question about any package using Context7. This helps to avoid the common problem of MCP cluttering context.
A pattern began to emerge in OrgChart where agent transitions and tool uses became events in a workflow. The transitions could be hooked into to apply transformations to the inputs, outputs, and contexts before continuing. Continuous context was the first example of this, and all of the ideas above can be modeled this way as well.
I also wanted to test Model Alloys, a concept from the team at XBOW where the same context is given to a random LLM during each conversational turn. They found that this yielded large improvements in output quality.
Finally, the current implementation of Continuous Context maintains an "in-memory docs" for the entire project, but it does little to help coordinate the actual context of all sub-agents. Thus a shared "brain state" could be kept which is updated from the context of each agent during agent transitions. This might enable agents to have greater team awareness of the work going on around them.
Learnings
What I found interesting about writing an LLM harness
My system prompts, tool prompts, additional features, or even using the SOTA models for every agent have not yet gotten OrgChart to a point where it's truly useful. That PlantUML example above took ~6 tries to get valid UML. Do I think it's impossible, or that the concept behind OrgChart is inherently flawed? No! In fact, I believe as OrgChart matures as a harness it will succeed. The coding agent world is beginning to adopt sub-agents more and more and I think that trend isn't likely to stop.
Heck, this post on Don't Implement Multi-Agents comes to similar conclusions as are implemented in OrgChart: where sub-tasking is serial and each agent communicates its assumptions, decisions, limitations, and results (see; AttemptCompletion tool prompt) of its work that it made during implementation
Regardless, I learned many of the ins and outs of coding agents and it was a fun project. Some of the learnings I found most interesting were:
If you give an LLM a task, even a simple one, but don't provide a "thinking" method, it will often fail. To provide a non-reasoning model the ability to think, you just make it produce output. OrgChart does this in two ways
- Agents must make and maintain a TODO list as they work. This is a no-op tool but forces the agent to reason about subtasks and delegation before doing anything.
- Every tool requires a "reasoning" parameter. Forces the agent to state why a tool is necessary which helps to prevent looping behavior.
These provide a dual purpose in letting the user track the intent of the agent as well as to enable the agent to think.
The same system or tool prompt applied to two SOTA models can yield completely different outcomes. Claude models can be steered very well with XML but other models will be confused by it. Thus the system prompt of an agent must be tailored to the specific model to achieve the best performance.
Additionally, API calls can fail, stall endlessly, or parse tool uses wrong such that tool XML ends up in the parameters. LLMs can not use a tool despite setting tool_use=required, invoke the same tool in a loop (Gemini!), provide no response at all, or provide invalid tool parameters. It's difficult to integrate with an interface that is non-deterministic and the best course of action upon one of these failures is also hard to know – do I just need to retry? Groom the context? Provide an additional prompt?
It's surprisingly difficult to get an LLM to identify the code it wants replaced. Just see the Cline team's blog post on the topic. Additionally I found that many times the model would try and fail to do something with a tool and simply fall back to bash commands and succeed. This is the premise behind the Terminus agent which is simply an LLM connected to a terminal.
LLMs want to be helpful and always provide an answer, they don't want to say no, say they couldn't find it, or state that it's not possible. Additionally, LLMs with tool-using capabilities are trained to use tools to accomplish the eventual goal of providing the user with a conversational response. So, you shouldn't design a harness that requires an LLM to fight their instincts.
Currently OrgChart requires an agent to use a tool on every conversational turn, a response without a tool use is treated as a failure and retried. This is an oversight because LLMs don't want to use AttemptCompletion to tell you that 2+2 is 4. I often saw "I don't need to use a tool and can provide the user with the answer directly" in my error logs.
Before I added the summarization flag to the bash tool, I implemented an agent called the Command Runner which was the sole agent with access to bash and a system prompt tailored around safety, but it would never reject a command. The Project Researcher agent will practically never state that it could not find the answer, despite its system prompt explicitly requesting exactly that. Most of the agents actually will not report the fullness of their failure when they could not fully complete a task.
So long as the tools you give an agent do what they should, the behavior of an Agent stems from the plain english tool and system prompts. There's no logic trace on why an agent does what it does, whether that all caps "DO NOT" you added did anything, or what percent of the time the agent will fail to use a tool properly. Very extensive and expensive evaluation would be required to perform tuning in the way I'd like. Without this evaluation knowing whether your prompts are good or even whether the mental model of your tools is properly tailored towards LLMs is a struggle (see: targeted edits).
OrgChart development cost me ~$270 in LLM credits, largely just from running "What's in tsconfig?" after each change to check for behavior changes, which I felt the need to do to evaluate holistically rather than deterministically so I could tune the behavior. It's difficult/useless to iterate on system prompts with a different model than you intend to use and each iterative test costs a few cents and it quickly adds up. I also did a few larger tests letting it run loose on a prompt like "Make a react app to play flappy bird" and, after writing 13 design files and many folders React code, I was left with 20 fewer dollars to my name and a web app showing a bird that couldn't fly.
v1.0 Roadmap
OrgChart is a work in progress
As with all software, the first 80% is 20% of the effort but I wanted to share the experiment, learnings, and future ideas early and iterate in the open.
I'm actively working on implementing the non-experimental features required for a daily driver coding agent and hope to get version 1.0 out with the following by the end of the year:
- Safety: It can read/write/bash with almost no safeguards
- Polished UI/UX: Macros like @ to reference files, configuration menu, stopping and resuming sessions or killing an agent
- Config Management: The configuration currently lives in a config file in the code, but needs to be able to read user and project level files as well
- MCP Support: I've yet to find MCP to be very useful in my own coding but a lot of people like it so I'll need that
- Extensive testing and benchmarking: Since this was all experimentation, the structure of the core code changed too often to justify maintaining extensive testing